Project overview
Cross-Nature Ontology is based on the Linked Open Data (LOD) technology and follows the structure of Plinian Core standard.

Plinian Core is a set of vocabulary terms that can be used to describe different aspects of biological species information. Traditional models for the biological description of species do not include aspects such as information of descriptions, legal aspects, conservation, management, demography, nomenclature or related resources with the described species.
In 2015 the IEPNB (Spanish Inventory of Natural Heritage and Biodiversity) approved the adoption of the Plinian Core standard as a structure for the storage, distribution and management of all species information.
Plinian Core is already accessible, autonomous, extensible and integrable, but can be much more enriched thanks to semantic web technologies. The application of these technologies to the existing model will enhance their possibilities and will put in value the great effort made to create this standard.
To carry out the evolution of the Plinian Core standard to a semantic model has been necessary to create an ontology: in standard formats defined by the World Wide Web Consortium (W3C).
Based on the axioms of the ontology model it will be possible to validate and augment information through automatic inference systems.
A complete interoperability between applications thanks to the Application Programming Interfaces (API) that are currently capable of processing and extracting conclusions about information published in semantic technologies.
This will lay the foundation of a service system that will be able to obtain and process information in a completely autonomous way. This possibility is especially useful in the interpretation of natural phenomena, cycles and their impact on species as they will lay the foundations of a system capable of publishing accurate and interpretable information by applications that can analyze and draw conclusions autonomously.
Linked Data allows building the Web of data, a large database interconnected and distributed on the Web. This is expressed in RDF format with expressions of the subject-predicate-object type, called triplets. Concepts or things described are identified by unique URIs to avoid ambiguities.
With this format it is possible to publish the data about the species with reference to the previously defined ontology. Current data has been transformed to RDF and stored in a platform that stores the triplets. This RDF server will have a point (Endpoint) accessible from the web for any person or machine in which the information will be consulted.
These queries will be performed using the SPARQL (Protocol and RDF Query Language).
It also follows INSPIRE specifications for geospatial information and express the ontology.
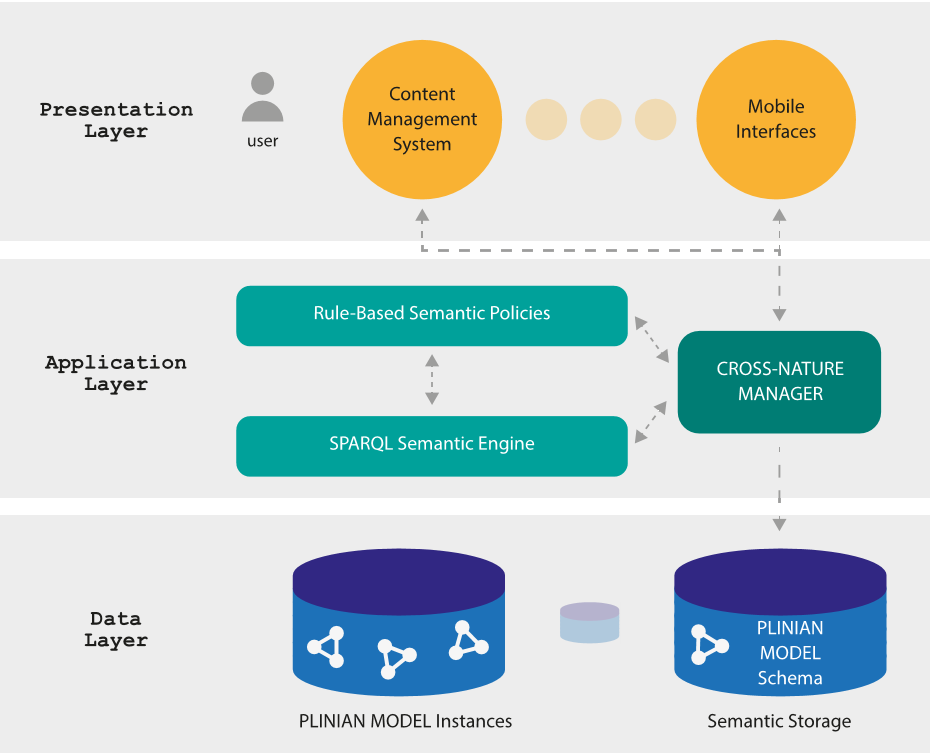
Cross-Nature Architecture
Workpackages of Cross-Nature project
WP2
REQUIREMENTS DEFINITION
This WP will research the interoperable architecture of Linked Open Data services among the different countries and the different sectos involved under a crossprocessing approach
WP3
DATA MODELING AND DATA PROCESSING
This WP will research the access, adaptation and harmonization of environmental and natural data to comply with the aim of biodiversity preservation and AIS (alien invasive species) monitoring and control, using Linked Open Data principles.
WP4
DATA PUBLICATION FACILITIES: ENDPOINTS AND DATA POPULATION
This WP will design and develop the semantic publication services involving the cross data modeling proposed.
WP5
EVALUATION OF RESULTS. DISSEMINATION AND EXPLOITATION
This work package will evaluate the CROSS-NATURE results and receive assessment from users and citizens feedback. In addition, it will maximize project impact and exploitation.
| MILESTONE NAME | ACTIVITIES INVOLVED | INDICATIVE COMPLETION DATE | DELIVERABLE No, | DELIVERABLE NAME |
|---|---|---|---|---|
| Management Foundations | 1 | 01/06/2017 | D1.1 | Quality Plan |
| MILESTONE NAME | ACTIVITIES INVOLVED | INDICATIVE COMPLETION DATE | DELIVERABLE No, | DELIVERABLE NAME |
|---|---|---|---|---|
| Technical Foundations | 2 | 31/12/2017 | D2.1 | Scenarios definition and Technical Foundations |
| 3 | D2.2 | Requirements definition | ||
| 4 |
| MILESTONE NAME | ACTIVITIES INVOLVED | INDICATIVE COMPLETION DATE | DELIVERABLE No, | DELIVERABLE NAME |
|---|---|---|---|---|
| Data exportation and publication | 3 | 31/12/2018 | D4.1 | Publication facilities – First version |
| 4 | D3.1 | Data models, vocabularies and Ontologies | ||
| 5 | D4.2 | Publication facilities – Final version |
| MILESTONE NAME | ACTIVITIES INVOLVED | INDICATIVE COMPLETION DATE | DELIVERABLE No, | DELIVERABLE NAME |
|---|---|---|---|---|
| Data publication | 3 | 30/04/2019 | D3.2 | Data exportation and publication |
| 4 | D4.3 | Data population and final systems | ||
| 5 |
| MILESTONE NAME | ACTIVITIES INVOLVED | INDICATIVE COMPLETION DATE | DELIVERABLE No, | DELIVERABLE NAME |
|---|---|---|---|---|
| Compliance with the Metadata Quality Assurance (MQA) tool for datasets | 1 | 30/04/2019 | D5.1 | Dissemination Plan and Dissemination Tools |
| D1.2 | Interim Report | |||
| D5.4 | Dissemination report - I | |||
| D5.2 | Dissemination report - I Initial results and project Evaluation |
|||
| 5 | D1.3 | Final Report | ||
| D3.2 | Data Exportation and Publication | |||
| D4.3 | Data population and final systems |

